rDigiOps delivers enterprise-grade Digital Operations that help companies standardize product data, validate FMCG labels, moderate digital content, and build AI-ready datasets. With hybrid human-AI workflows and deep domain expertise, we ensure accuracy, compliance, and scalable intelligence across global operations.
Four-tier QA: automation checks, domain specialists, peer review, final audit.
20+
Languages Supported
Native speakers ensure cultural, linguistic, and regulatory accuracy.
2000+
Professionals
Domain experts, moderators, annotators, and AI dataset specialists.
95%+
On-Time Delivery
SLA-driven operations across global delivery centers.
Digital Operations Services We Offer
Content Management Services
Standardized Product Data for E-Commerce Excellence
We deliver end-to-end product content operations for retailers, marketplaces, and global brands. Our teams centralize PIM data, structure product catalogs, and harmonize taxonomies, ensuring every SKU is accurate, enriched, and commerce-ready.
Core Capabilities:
Centralized Product Information Management (PIM).
Product catalog structuring and taxonomy alignment.
Pricing synchronization across channels.
FMCG Product Labeling
Accurate, Compliant Multi-Language Label Data
We support global FMCG brands with complete label-data workflows, from packaging annotation and OCR extraction to multilingual validation and regulatory compliance checks.
Core Capabilities:
Image annotation for label zones and design elements
Safe, Compliant & Trustworthy Digital Environments
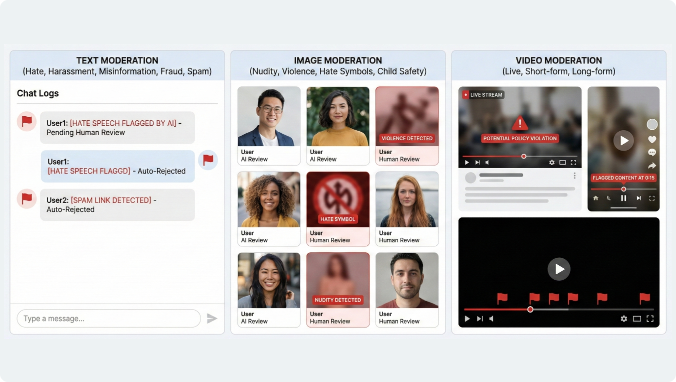
We manage trust & safety programs for platforms with user-generated content, ensuring safety, compliance, and brand protection through hybrid AI + human workflows.
Core Capabilities:
Text moderation for hate, harassment, misinformation, fraud, spam.
Image moderation for nudity, violence, hate symbols, and child safety.
Video moderation (live, short-form, long-form) covering:
Visual content analysis
Text overlay detection
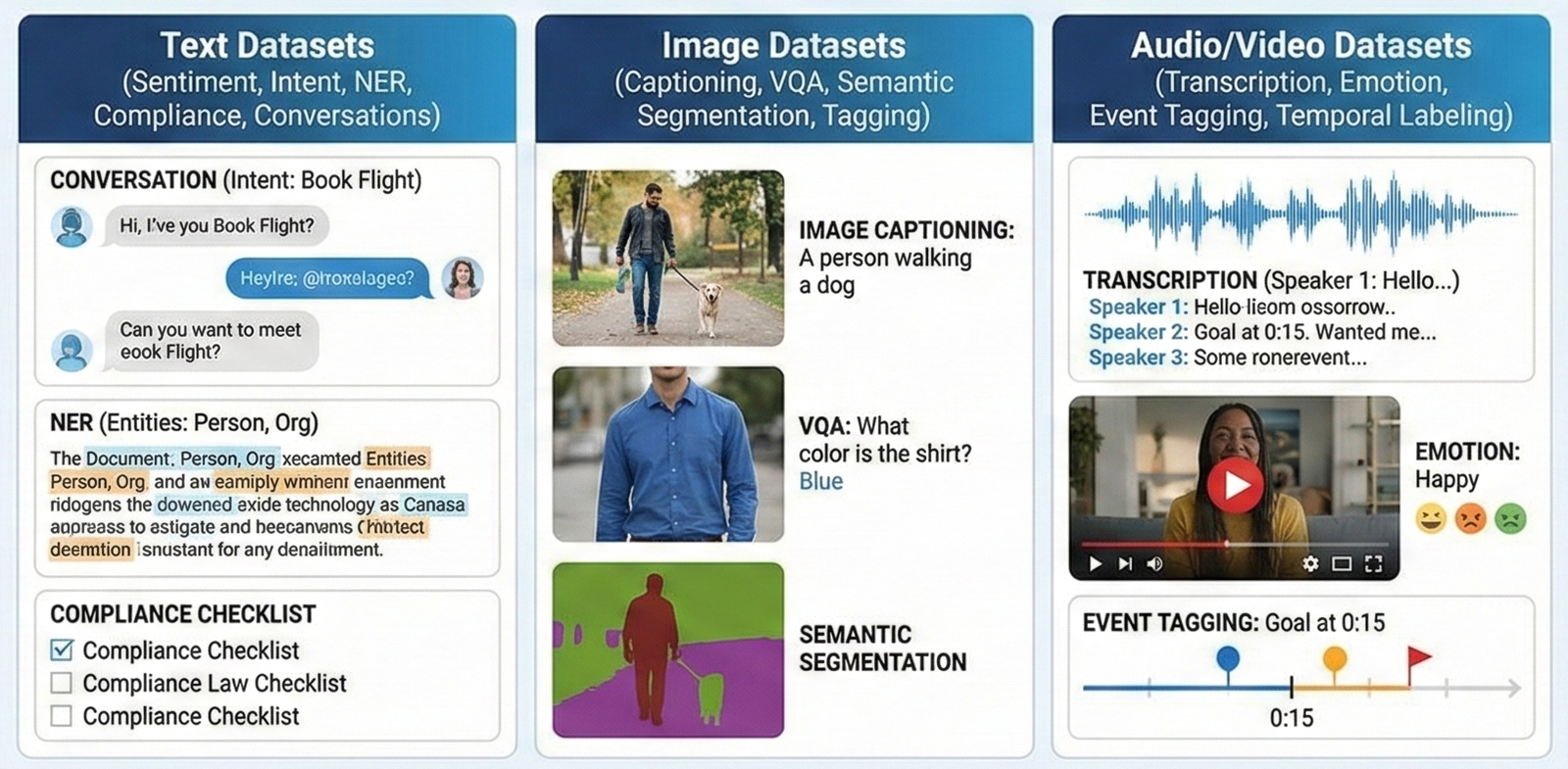
GenAI & NLP Data Services
High-Quality Data for Next-Generation AI Models
We prepare structured, production-ready datasets for LLMs, vision AI, and multimodal models across text, images, audio, and video.
Core Capabilities:
Text datasets: sentiment, intent, NER, compliance, conversations.
20+ languages supported by trained native speakers.
Secure & Compliant
ISO 27001, ISO 9001, TISAX, GDPR, and RBA-aligned operations.
Case Studies
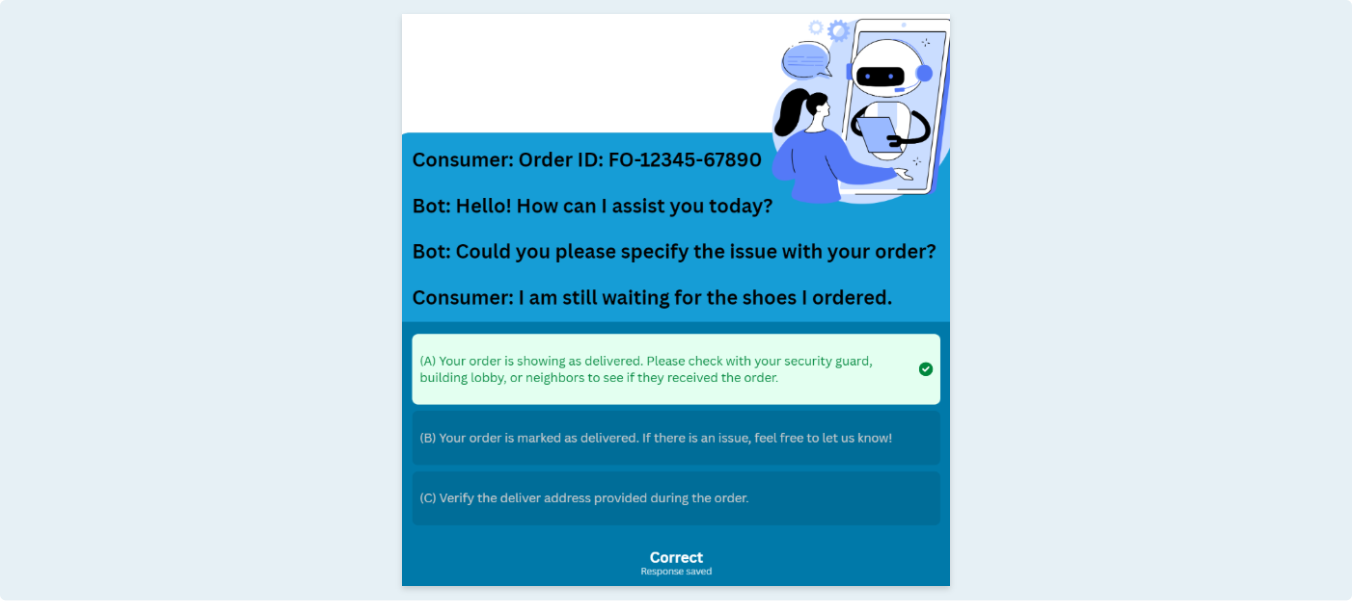
Retail customers experienced inconsistent chatbot responses that were repetitive, irrelevant, or failed to resolve queries effectively. This led to reduced engagement, drop-offs during conversations, and lower overall conversion rates. The client required high-quality RLHF-ready conversational datasets to improve decision-making, contextual understanding, and response accuracy within their chatbot system.
Reviewed and analyzed complete customer–chatbot conversations to understand intent and context.
Identified the most relevant, non-repetitive, solution-focused responses for RLHF training.
Categorized chatbot outputs as Solution-Oriented, Repetitive, or Irrelevant.
Flagged conversations with poor chatbot behavior (loops, hallucinations, incomplete replies).
Curated high-quality responses aligned with conversational best practices to strengthen model training.
Processed 120,000+ conversations and delivered 350,000+ curated responses.
Improved chatbot accuracy by 37% through high-quality RLHF datasets.
Reduced repetitive responses by 44% and improved first-response resolution by 29%.
Enhanced multi-turn contextual understanding by 52%.
Achieved a 92% dataset quality score, enabling stronger conversational AI performance.
Enabled higher customer engagement and improved conversion rates for retail interactions.
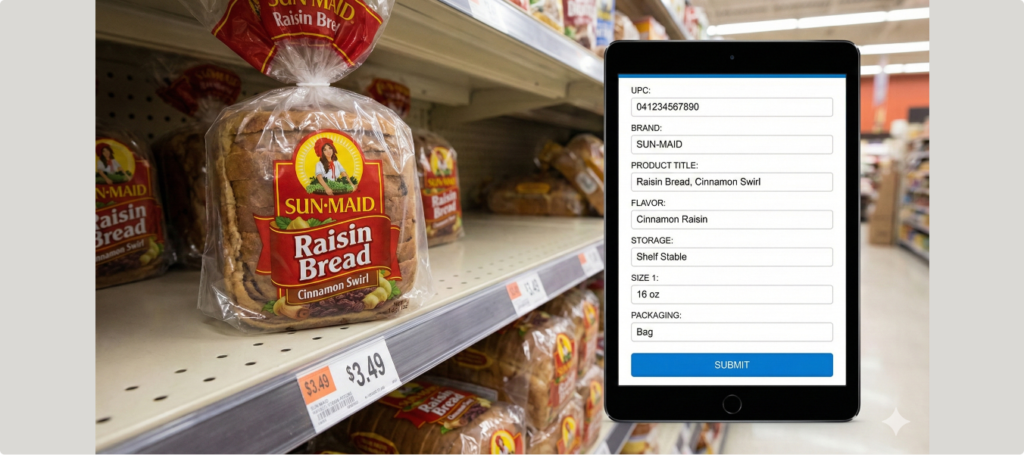
Accurate extraction of product details from packaging is essential for retail onboarding, compliance, and marketplace listings. However, multilingual labels (English, German, Japanese), varied packaging designs, and OCR inconsistencies make it difficult to reliably capture ingredients, nutritional facts, warnings, pricing, barcodes, and certification information. This leads to data errors, manual rework, and delays in product catalog creation.
Annotated product packaging using bounding boxes and segmentation to precisely isolate text regions.
Applied OCR-based extraction to capture ingredients, nutritional details, pricing, expiry dates, barcodes, and certification info.
Conducted multilingual validation (EN/DE/JP) against databases, standards, and manufacturer instructions.
Performed quality checks and corrected OCR outputs to ensure regulatory accuracy and clean structured data.
Processed 80,000+ product images across multilingual labels.
Validated and corrected 150,000+ extracted text fields.
Achieved 89% multilingual OCR accuracy and 96% QA-approved final output Enabled faster and more reliable product onboarding for retail platforms.
Reduced manual correction time by 56%, improving operational efficiency.
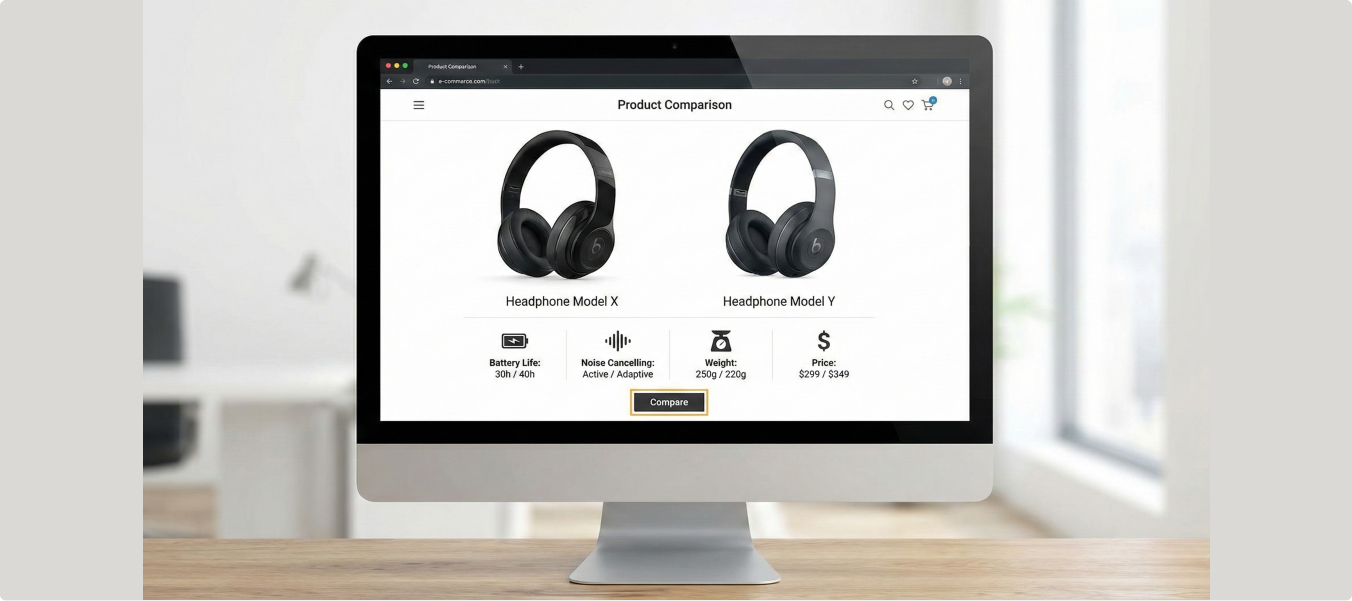
A global e-commerce platform struggled with accurate product matching across millions of SKUs due to variations in size, visuals, materials, patterns, and descriptions. This resulted in duplicate listings, pricing inconsistencies, misclassification of products, and heavy manual review efforts. The client required a scalable Human-in-the-Loop (HITL) solution to support high-volume, attribute-level product comparison with frequent rule updates.
Reviewed paired and grouped product listings to determine Same vs Not Same.
Compared key attributes across physical, quantitative, and functional categories.
Enriched product visuals, attributes, and metadata using structured annotation workflows.
Ensured consistency through standardized guidelines and controlled QA.
Adapted quickly to frequent rule and policy updates.
Completed 13+ million product comparisons within 5 months.
Deployed 80+ trained annotators with continuous 365-day operations.
Significantly improved product matching accuracy and catalog integrity.
Reduced duplicate listings and pricing discrepancies across categories.
Accelerated onboarding of new products with attribute-rich comparison data.
Before
After
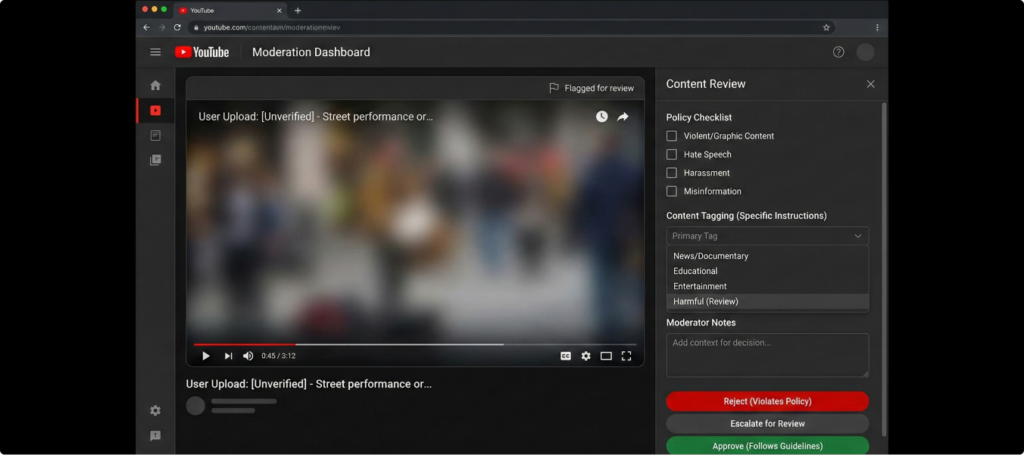
A major online platform needed to moderate millions of user-uploaded videos daily to ensure compliance with community and legal guidelines. The scale and subjectivity of content led to inconsistent moderation, difficulty identifying varying risk levels, and increased exposure to harmful or sensitive material. The client required a scalable, policy-driven workflow for accurate video flagging and categorization.
Reviewed full video content to evaluate context, tone, and intent.
Analyzed audio, visuals, captions, and behavioral cues holistically.
Classified videos into clear risk categories: Appropriate, Slightly, Moderately, and Extremely Inappropriate.
Applied detailed moderation guidelines to distinguish mild violations from severe harm.
Tagged content for safe publishing, restriction, or escalation.
Ensured consistency through standardized processes and QA controls.
Processed and categorized hundreds of hours of video content across risk levels.
Improved early detection of harmful content by 40%.
Reduced manual review effort by 35% through structured categorization.
Enabled consistent, guideline-aligned moderation decisions at scale.
Strengthened user safety and platform trust while supporting future automation.
Before
After
rDigiOps - FAQs
What types of data and workflows does rDigiOps support?
Everything from product catalogs, FMCG labels, and digital content to text, audio, video, and multimodal AI datasets.
How is rDigiOps different from generic BPO vendors?
We are domain-led with specialists, structured ontologies, 4-tier QA, and deep expertise in compliance-heavy and AI-critical workloads.
How do you ensure accuracy and consistency?
Through automated checks, specialist review, peer QC, final audit, and inter-annotator agreement tracking.
Do you support multilingual workflows?
Yes, 20+ languages supported by native speakers trained in cultural nuance and domain-specific terminology.
How do you handle compliance-heavy use cases?
We follow global frameworks (FDA, EFSA, Codex), platform policies, and strict moderation guidelines with secure, controlled-access operations.
Can we begin with a pilot?
Yes. Most pilots are 200–500 samples or a limited-scope workflow before full-scale deployment.
How do you ensure data security?
ISO 27001-certified environments, encrypted handling, NDA-bound teams, GDPR alignment, and zero-retention options.
How is pricing structured?
Per-unit, per-hour, or dedicated-team models depending on complexity, volume, language, and SLAs.
Ready to Transform Unstructured Data into Enterprise Intelligence?
Partner with rProcess for enterprise-grade digital operations across product content, FMCG labeling, content moderation, and AI dataset preparation.